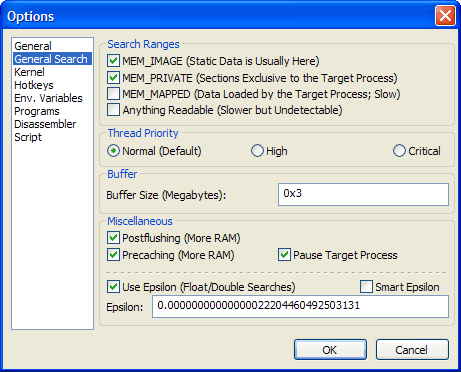
There are many search options available to help increase the performance of MHS’s scan speed, and the options may perform differently from one computer to the next.
The following table explains each option.
Option
Meaning
MEM_IMAGE
Include chunks with type MEM_IMAGE.
When executable files and modules are loaded into RAM, they are broken into parts and mapped over the RAM. The sections used to map them over RAM are given the MEM_IMAGE type. Executable files are usually loaded to the same address on each start-up, making its MEM_IMAGE sections static.
MEM_IMAGE types are always considered static, even if the module owning them moves in RAM, because each MEM_IMAGE section that is part of the module will always start at the same offset from the base of the module, thus any address in the module that lies inside any of its MEM_IMAGE chunks can always be calculated.
MEM_PRIVATE
Include chunks with type MEM_PRIVATE.
MEM_PRIVATE chunks are chunks of memory allocated by the target process that are not shared by other processes. Static pointers are always found in MEM_IMAGE chunks, and usually point to dynamically allocated MEM_PRIVATE chunks.
MEM_MAPPED
Include chunks with type MEM_MAPPED.
MEM_MAPPED chunks are chunks that are mapped to files on hard drives. Operations (read/write) performed on these chunks in RAM are also performed on the relative files on the hard drive, making these chunks slow to search. They generally have nothing to do with the values in RAM you want to find and are best left out of searches.
Anything Readable
Includes all readable chunks. This is roughly the same as checking MEM_IMAGE, MEM_PRIVATE, and MEM_MAPPED, except that it creates the chunk list (to search) using a different algorithm. This option can not be used with the other chunk options.
The algorithm used by this option is slower than the normal algorithm but provides one particular benefit which may be of great importance depending on the target process. The algorithm used by this option is extremely difficult for the target process to detect and block, and therefore this may be the only way to search the RAM of the target process.
If this opion is not used, and the algorithm that generates the normal chunk list returns 0 chunks, the chunk list is automatically regenerated using this algorithm.
Pause Target Process
Pause the target process before searching. This improves speed considerably on processes that consume many computer resources.
Do not use this option on system processes such as csrss.exe.
Buffer Size
The size of the internal buffer used to hold found addresses in RAM. When this buffer is full, the data must be flushed to a file to free RAM for more returns while the search continues.
Flushing has a considerable impact on speed. The fastest searches are obtained by creating a buffer large enough to hold all returns in RAM, which will never cause a flush to take place.
Flushing never occurs in Unknown searches or in Exact Value searches where the value is not a 0 or a -1.
Precache
Used only in Sub Searches. While in a Sub Search, data from the previous search may need to be loaded into RAM from disk (if the initial search did not flush any data, the values will already be in RAM and this option will have no effect). This option will cause a second thread to run in the background which will load the next buffer from the file while the current buffer is being scanned. Optimally, the scan will finish with its current buffer and the precached buffer will be loaded and ready to go for the scan to continue.
The size of the precached buffer is the same as the size set in Buffer Size. This means that the total RAM needed for this option is double Buffer Size.
Postflush
When there are enough returns in a search to overflow the Buffer Size, the buffer must be flushed to disk. This option allows the flushing to take place on a second thread in the background so the scan can continue smoothly.
This can happen in both Searches and Sub Searches. Using this option will require double the RAM specified in Buffer Size, but only if a flush takes place.
Thread Priority
Set the thread priority for the scan. Different processors respond to this option differently. AMD® processors rarely show a difference between the priorities, while Pentium® processors show slight improvement with higher priorities.
Using higher thread priorities can sometimes negate the benefits of using Postflush and Precache. This is because the scanning thread may block the flushing/caching threads, not allowing them to perform their operations by the time the scanning thread is ready for the next flush/cache. When this happens, the scanning thread automatically adjusts its priority to give the other threads room to do their jobs, however the scanning thread must wait for them to finish before it can continue.
Users should experiment to find out if higher priorities are beneficial to them.
Use Epsilon (Float/Double Searches)
Rounding errors in floating-point numbers (types Float and Double) cause some searches to find no matches even though you typed the exact number you saw. For example, you search for 1.3509 but the actual value is 1.350901002.
Epsilon is used to account for this. When you search for a floating-point number, all values within Epsilon range of that number will be added to the list, allowing you to account for the tiny rounding errors to which CPU’s are proned.
Smart Epsilon
It is common for rounding errors to be present in CPU math, especially with infinite decimal places. However there are sets of numbers that typically round off very well and accurately. For example, the number 1.0 is often represented accurately on machines, with no trailing decimal places.
When Smart Epsilon is checked, Epsilon will be disabled for searches that are detected as rounding very well
Details
Buffers
Because the searches can depend heavily on threads, the actual options vary greatly between processors. Pentium® users may find a smaller buffer (0x01 to 0x05), with Precaching and Postflushing enabled, to be very smooth and at nearly no loss in speed. AMD® users will probably want to use a middle-sized buffer (0x10-0x25). These numbers are also subject to change given resource availability and other factors, and experimentation is necessary to find the best options for you.
Flushing
Flushing is the process of writing the values stored in RAM to the hard drive, and then removing the values from RAM to make room for more values. Buffer Size is the primary factor in deciding how often the internal buffer must be flushed.
If the Search Type is set to Unknown, no flushing takes place.
If the Search Type is set to Exact Value, and the value to find is not a 0 or a -1, no flushing takes place. If the value is a 0 or a -1, flushing occurs as needed.
Storage Efficiency
All memory scanners use two methods for storing found addresses internally.
The base method is to store address/value pairs where the address takes 4 bytes and the value takes as many bytes as needed for the search type. For example, each found address in a byte search would require 5 bytes to store. This is the least efficient in terms of space.
The other method is used only in Unknown searches where the address is stored once and the entire chunk of returns follows. This is the most efficient means possible of storing the returns, however it only works in Unknown searches.
MHS uses a third type to store returns, as well as the previous two.
The third method allows MHS to store values equally fast as the first method but using much less storage space. The details regarding the inner workings of this method are strictly confidential.
The special storage method allows the same number of returns to be stored in up to 50% less space, which causes flushing to occur less frequently, and less disk space to be used. Because flushing is the largest factor in slowing search speed, and because this method causes substantially fewer flushes with no loss in general search speed, this method is responsible for giving MHS the fastest data-type searches possible.
In Data-Type searches, this method is only used in Not Equal To, Greater Than, Lower Than, and Range searches, and Exact Value searches if the value is 0 or -1. In all other types of searches aside from Data-Type, this method is always used.
Only this method is capable of flushing and caching, thus Precaching and Postflushing only work on the search types listed above.
Other
In Data-Type searches, if a Range search is used and the specified range covers the full range of the data type, the search is internally changed to an Unknown search for better performance.
To increase performance, if the first Sub Search is a Same as Original sub search, the search type switches internally to a Same as Before sub search. This avoids rebuffering the initial results, which consumes more RAM and causes slower searching.
To benchmark MHS against other software, select the Range search in both software and specify data-type Byte with a range from 0 to 254—this range is meant to get a huge number of returns without causing MHS to switch to an Unknown search type. Be sure similar options are being used in both software and that a similar number of results is found.