Address calculation is one of the largest parts of Stored Addresses. MHS offers 3 methods for calculating them. Each method offers different pros and cons. The best method should be chosen on a per-item basis.
First 2 of 3 Methods
Before discussing the actual options, it is important to understand base addresses, final addresses, and complex addresses.
Base Address vs. Final Address
Address calculation is normally broken into two parts: the base address and the final address. The base address is the first address when following multiple pointers down a path (a pointer tree). Usually this is a module.exe+offset combination, but is also commonly a simple address. After the base address, be it a module.exe+offset combination or a direct address, if no more processing needs to be done to calculate the address of the item, then the base address and final address are the same.
In items that are multiple pointers “deep” (items that require a series of pointers to be examined and followed to get to the target address) must do extra processing after the base address. This processing is used to get the final address.
Complex Addresses
The term complex address actually refers to the format of a text string used to calculate addresses that are multiple pointers deep, or require other forms of extra processing. The string format allows basic math operators in conjunction with module names, which are replacements for their actual addresses, and the [ ] bracket operators, which indicate that after the value inside the brackets is determined, that value should then be considered an address inside the target process and the value at that address should be obtained. In MHS, all valid expressions can be used as complex addresses.
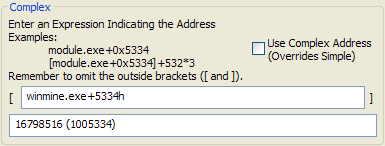
For example, winmine.exe+0x5334 might give us the value 0x01005334. [winmine.exe+0x5334] would be turned into [0x01005334]. Then 0x01005334 is considered an address inside the target process and the value is read from that address (in DWORD form), which might return the value 30.
Typically when writing a complex address, you want to leave off the outside brackets, because we aren’t interested in the value at that address, but the actual address itself. There may be exceptions, however, and you may use the outside brackets as needed. The Normal Address dialog reminds you to omit the outside brackets, however you may break this rule as you see fit.
Simple
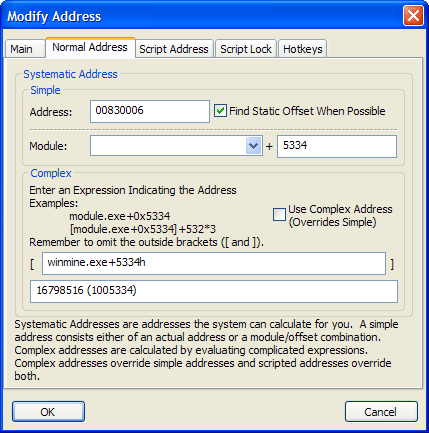
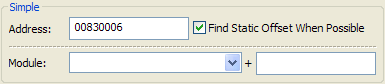
MHS has built-in functionality for making the computation of a simple address extremely fast and efficient.
The simple address can be either a direct address or a module.exe+offset combination. Both require the same amount of time to calculate (one operation), so choosing a direct address instead of a module.exe+offset address is never better. Find Static Offset When Possible will calculate the module.exe+offset format for you. If unchecked, or if no module.exe+offset format can be made, the direct address is used.
This method can only calculate the base address. When using only this method, the base address and final address will always be the same.
Complex
MHS has a built-in parser for quickly calculating complex addresses.
A complex address stores both the base and the extended information for the final address. Any expression can be used to get the final address, and nothing special must be done to denote any part of the expression as being the base address.
Examples of valid expressions include: winmine.exe + 0x5334 [[[[tutorial.exe+C4208]+C]+14h]]+18LH ([[Project64.exe+D6A3C]+62988lh]&0xFFFFFF)+[Project64.exe+0xD6A3C]+2D4
Resolving complex addresses into actual addresses is fast and efficient. Text parsing is performed only once and all values are simplified when possible. Expressions that do not have module names or [ ] operators are all calculated at the exact same speed, equivalent to the speed of the calculation of the simple addresses. Therefore, parsing the expression 45 * 2 + 0x01005334 is just as fast as parsing the expression 0x100538E; both take only one operation, and therefore both are also just as fast as parsing the simple addressmodule.exe+100538E, which is again just as fast as parsing the direct address0x0100538E.
Complex addresses contain both the base and final addresses. When a complex address is being used, the simple addresses are not used at all, however the data for the simple addresses remains and can be modified. When the complex address is disabled, the simple address is used again. The data for the complex address remains and can be modified, however it is only actually used when enabled.
Although complex addresses contain both the base address and the final address, the base address is in no way denoted inside the expression, and therefore the entire expression is technically implemented as the base address.
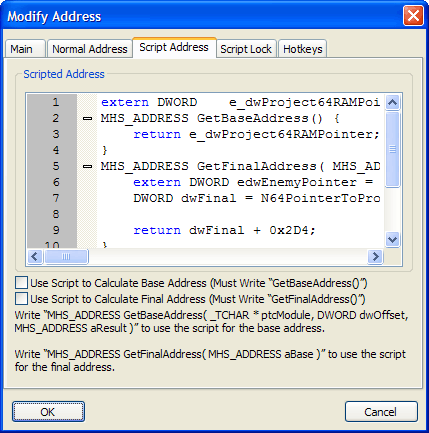
Scripted Address
Scripted addresses are the most complicated address-calculating systems available. They allow you to perform any operations required to get the address of the item.
You can write scripts to get the base address, final address, or both. Complex addresses override simple addresses and scripted addresses override both. However, both simple addresses and complex addresses are used only for base calculation, and it is therefore possible to use either the simple or complex address in conjunction with the scripted final address.
As mentioned before, the information for a simple address remains, even when simple addresses are not being used. When complex addresses are used, the information in the simple address is simply not used at all. However, when the scripted base address is used, the module, offset, and result from the simple address is passed to the GetBaseAddress function.
Finally, the base address is passed to the GetFinalAddress function, no matter which method was used to calculate it. Therefore, it is possible to use the scripted final address with the base (parameter aBase) calculated as a direct address (from the simple address), module.exe+offset combination (from the simple address), complex address (from the complex address) or as a scripted base address.
The GetBaseAddress and GetFinalAddress functions should simply return the base address and final address of the item. In all cases, the final address is what is used to determine the actual address of the item, therefore it is not required to write both functions. You could write only GetBaseAddress, and its value will be used as the final address also, or you could simply write GetFinalAddress, and even though there is no base address it would still return the only value that matters in the end: the final address.
ptcModule is the module specified in the simple address. dwOffset is the offset supplied in the simple address. aResult is the result of ptcModule+dwOffset, where ptcModule has been converted to the actual base address of the module. These values are taken from the simple address data, even if the simple address is not being used. This data can greatly enhance the speed of calculating the base address.
aBase is the previously calculated base address. The value here could have come from any method available for calculating addresses. If simple addresses are used, it will be the direct address used, or the result of the module.exe+offset combination. If complex addresses are used, it will be the result of the expression supplied for the complex address. If the scripted base address is used, it will be the return of the GetBaseAddress function.
The parameters in GetBaseAddress and GetFinalAddress are optional, however they must remain in the correct order when used. For example, it is okay to omit aResult, but dwOffset may only be omitted if aResult is omitted, and all parameters that are used must be in the correct order. It is actually advised that unneeded parameters be omitted, as this will actually make it slightly faster to call the script function (though the difference is nearly infinitely small).
Pros and Cons
The following chart explains the pros and cons of each method.
Method
Pros
Cons
Simple Address
Easiest to use/understand.
Never slower, and usually faster than the other methods.
Allows data to follow modules as they move in memory.
Usually consumes the least amount of disk and RAM space.
Only allows one depth of addressing—unable to follow pointers to the target.
Complex Address
Easiest way to map a series of pointers that must be followed to the target address.
Consume less RAM and disk space than script addresses.
Always faster than the
equivalent
script address.
Allows all standard mathematical operations, enabling it to track virtually every pointer tree, including encrypted ones.
Unable to follow some pointer trees if extensive encryptions have been placed on them.
Unable to use logical branches while following pointer trees.
Script Address
The end-all-be-all method for calculating the target address; no encryption is too great.
Allows logical branching while calculating the pointer path.
Consumes much more RAM than the other two. However, if the script lock is already being used, adding script addresses consumes relatively little extra RAM, sometimes less extra RAM than the RAM needed for a complex address.
Typically, though not always, consumes more disk space than complex addresses.

 A complex address stores both the base and the extended information for the final address. Any expression can be used to get the final address, and nothing special must be done to denote any part of the expression as being the base address.
A complex address stores both the base and the extended information for the final address. Any expression can be used to get the final address, and nothing special must be done to denote any part of the expression as being the base address.